原创 亲爱的数据 亲爱的数据
漫画图文原创:亲爱的数据

好几年没写AI框架大稿了,
我先把结论放在标题里,
若想细看其中原委,
只能说,大几千字阅读量是跑不了的。
01
灵魂三问
PyTorch最近有点烦,
历经多年码海沉浮,
拼快慢,争静动,
较难易,掀生态。
看似地位稳如泰山:
“主流框架”
“事实工业标准”
“生态百花齐放”,
开发者“箪食壶浆以迎王师”,
“框架”作为AI这个热门赛道里的基础软件,
如果愿意多花点时间观察,
你就会发现,时间花完,
虽然没看懂,但起码累着了。
在此,要向这几年参与AI框架技术的大牛们致敬,
还要向全球开源框架开发者致敬,
感谢你们贡献了开源。
AI芯片需要框架翻译才能释放性能,
AI生产力需要框架解放。
人间为饮千岁,吞吐江海流霞。
近五年,我很多好朋友都出自这个领域,
感谢他们的认可,这是我写作的不竭动力。

我长话短说,
不过,实在是说来话长。
变量太猛,战局有变。
先来个灵魂三问:
1. 北美大模型玩家也被PyTorch统一了吗?
2. 谁在掏空PyTorch?
3. 开发者视线转移意味着什么?

02
游戏结束了?
"The game is over.”
直译:游戏结束了。
意译:除了PyTorch,别的AI框架玩家都没机会了。
这是某网友对AI框架战局的评语。
我只能说,情绪到位了,逻辑还差点意思。
甚至说,是仅仅观察了国内市场后得出的结论。
先看数据,
PyTorch一统江湖。

不得不说,真是帅啊。
再帅也有烦的时候。
因为整体市场占有率是一回事,
巨头份额又是另外一回事。
当然,无论什么底层软件,都想上大业务。
那么问题来了,
大模型巨头玩家到底在用哪种AI框架?
尤其是,巨头玩家的偏好和中小玩家不同。
巨头玩家要的不是一个“现成的万能工具箱”,
而是一个“按需定制的军火库”。
OpenAI用的是PyTorch,
但几乎重写了底层逻辑,
以适应自己的大模型架构。
谷歌用JAX,它为TPU量身定制。
华为用MindSpore框架,
背后是昇腾AI处理器。
为什么不继续用PyTorch呢?
开源框架是基础,不是答案。
开源框架适合普通开发者,
而巨头们往往需要在此基础上深度定制。
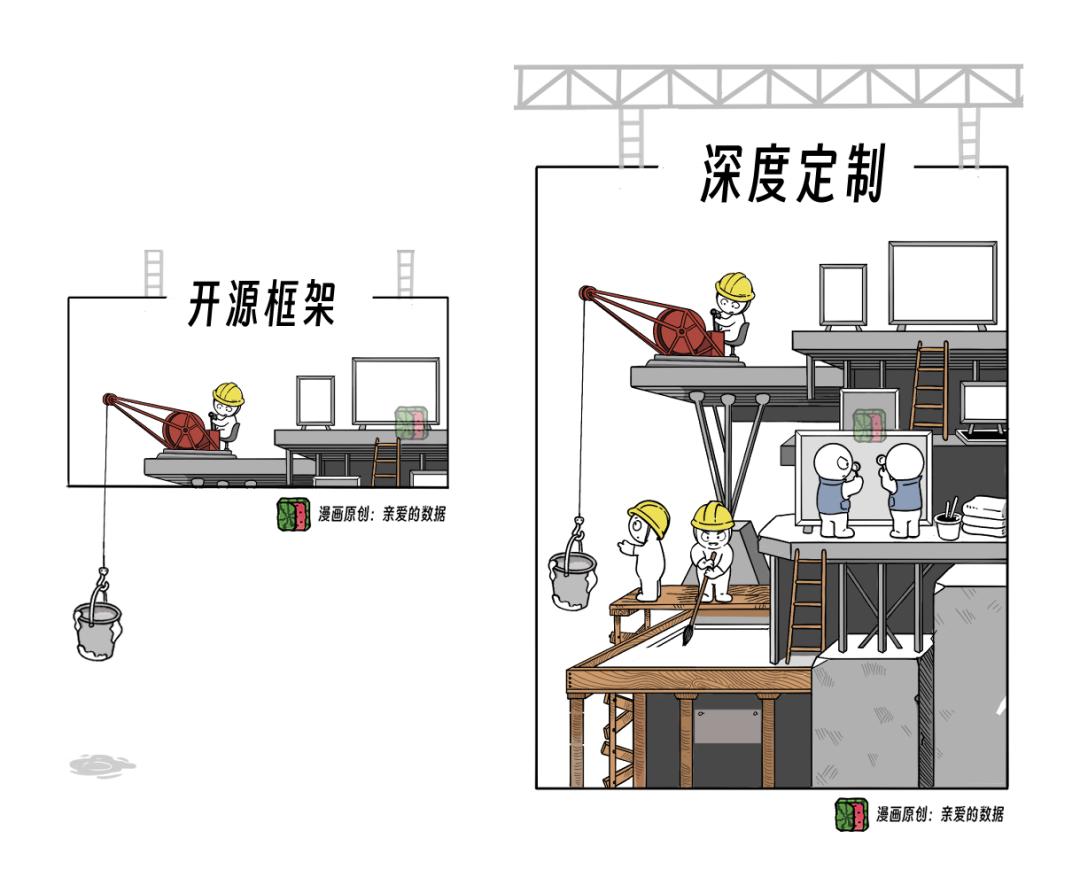
PyTorch作为框架“一哥”,
并不能保证它的原生版本,
就能直接满足GPT-4或Llama3的全部需求。
所以,当你问“大模型巨头用什么框架”时,
真正的问题应该是:
这些巨头在训练和推理大模型的时候,
到底用的什么秘密的框架技术?
答案可能不会直接写在开源框架的市场份额里,
而是藏在巨头们自家技术栈的深处。
这个时候,谭老师就出场了。
直接人到美国,现场做题,
当然,答案仅供参考。
美国巨头的几家,我们掰着手指头数数看。
谷歌,Anthropic,xAI,苹果,这四家训练大模型用JAX,
另外两家,Meta和OpenAI,用PyTorch。
这个大致的调查结果,非常神奇:
北美大模型巨头的框架份额排第一的是JAX。

此时此刻,回望大洋彼岸,
国内模型框架仍然是PyTorch占据主流。
我只能感慨一句,
在框架这件事上,有些人保守了。
再看国内国产框架,几年来,
MindSpore和“洋框架”打了不少张场仗,
虽然没有占过上风,
但忍耐力还不算坏。
这时候,我又想给这个小章节重新拟个标题了,
《北美市场已生变数,国内持旧观望》
——在不疑处生疑。
越是有人毫不怀疑地用PyTorch,
越要重新审视。
03
不吃生态
这碗饭?
在我个人的写作史上,
四年前那篇《搞深度学习框架的那帮人》,
其中大量篇幅在聊框架生态。
然而,时过境已迁,
身处大模型时代,
如果拿生态来衡量JAX,
实话实说,JAX也没啥生态,
它的论文数量还没有MindSpore多。
(此处不礼貌地笑了)
堂堂谷歌,堂堂华为,
框架生态都矮“一哥”一头。
接着灵魂发问:
为啥JAX在大模型巨头玩家中的份额这么高呢?
因为大模型框架对原来的那种生态,
可能要求没那么高,
反倒对性能调试调优的效率要求高。
也就是,不吃生态这碗饭,而吃效率这碗饭。
往细里讲,训练时你写个模型脚本不重要。
关键是你能把这个系统的性能,
调优的效率,精度的对齐,打出水平。
模型脚本是什么呢?
它是告诉框架“这个模型应该长什么样”的说明书。
而在大模型时代,系统性能和训练效率成了重中之重。框架需要提供强大的分布式训练支持,稳定和性能压倒一切。巨头玩家搞大模型的时候,
对框架的要求和以前相比出现了巨大变化。
平静的大海培养不出优秀的水手。
回到此前结论,重要的事情说三遍:
变量太猛,战局有变。
04
为啥谷歌JAX
框架这么行?
众所周知,TensorFlow在大规模生产部署中,
仍具有技术优势,市场份额也有。
尤其是其与TPU芯片深度整合,
继续占据一席之地。
不过同为谷歌系的框架,
TensorFlow框架有很多历史遗留问题,
而JAX框架低调地风生水起。

第一点,谷歌JAX框架设计简洁,
不像TensorFlow框架设计复杂。
第二点,谷歌JAX一开始就是静态图,
且擅长静态图。
静态图天然适合科学计算和大模型的优化需求,
并延伸出自动并行。
同时,静态图也是自动并行的基础,
为其提供了全局视图和优化空间。
于是,水到渠成第三点,
JAX的自动并行非常能打,
是在静态图打下的好基础上做到的,
有一套强大的自动并行工具。
对比PyTorch框架,早期没重视并行,
以至于给了第三方背后开枪的机会。
(姑且按下,容后细述)
细看谷歌JAX,再看一眼昇思MindSpore,
气质上很像,想法也总一样,
它们都从一开始就考虑在框架上支持并行。
我甚至愿意下这样一个结论,
当年,谷歌JAX和昇思MindSpore,
对并行考虑得多,
就是预测模型会变大。
而今看来,一切成真。

当然,还有一点非常重要,
是一窥当下框架竞争态势的要点:Numpy。
Numpy是个好东西,甚至是越看越好。
你可以记不住它,
也可以永远用不到它,
但请别忽略它的价值,
它的价值不是能用钞票衡量的,
不仅在人类科学工具发展历史上占有一席之地,
而且什么都不争,克制低调,
实际却是整个江湖的发源地,
甚至间接推动了AI框架的崛起。
在AI框架出现之前,
它是唯一的选择,
Numpy为矩阵计算提供了最初的接口和工具。
然而,它不是PyTorch的选择,
你看,JAX选了Numpy,
苹果也选了Numpy,这可不是巧合。

为什么?
Numpy中立,且兼容性强,
甚至可以说它是一种科学计算领域的公共语言。
JAX选Numpy,
苹果选Numpy,
再反观PyTorch,虽已一统江湖,
但在设计上与Numpy渐行渐远。

当谷歌JAX和苹果这两家代表未来趋势的选手拉起Numpy站队时,
PyTorch反而被推向了一个“孤立”的处境。
更关键的是,Numpy的中立让它成为“公共资源”,谁都能拿来用。
但当你的对手都用这个公共资源来增强自己,
而你却在构建别的,
这江湖里的对抗就不只是暗流涌动。
我们能看到,谷歌JAX和苹果的选择,
其实是对PyTorch的一个有力提醒。
还没聊完。
还要深入静态图和动态图的江湖。
不过且慢,我在硅谷遇见了一件小事,
于是,在话题出发前,
我们绕道去下这里“API”。
05
谁敢小瞧
框架API?
框架的API是啥?
API可翻译成“接口”。
不过此接口,非彼接口,
再讲那件小事。
某天,约见了一个程序员,
虽然他不搞AI,
但正巧我在写这篇稿子,
聊一句框架的API。
他信心满满地跟我说:
“API不就是调用一个服务嘛,多老的东西了。”
而他说这话的表情吧,
就像揭露了你炒作技术概念。
当时,我真是……
所以,大家不要对美国硅谷全是滤镜。
话说回来,
框架API它不再适用于之前那么单薄的理解了,
那是整层技术栈的总指挥。
纵观历史,唏嘘不已,
框架每一轮竞争都离不开“接口的博弈”。
可不是让“程序和程序对话”,这么简单,
而是,从“开发工具”变成了,
“开发体验”和“硬件性能”的代名词。
谁的接口设计得好,谁首先就能抓住开发者。
框架接口的好坏,直接决定了一个框架的受欢迎程度。比如,屎堆型界面,谁也受不了。
早期TensorFlow,也因此跌倒。
因为太过复杂,被PyTorch抢了很多市场份额,
所以,你说,框架接口重不重要呢?

以前,调用一个服务。
现在,表面只是调用一个服务,
背后调度几十台GPU拼命算矩阵乘法。
甚至,框架的接口规模很大,
一个完整的生态系统可能需要上千个接口。
那么问题来了,
PyTorch有多少个接口?
答案是:一千多个。
说到这里,如果MindSpore和其全部对齐呢?
很困难,工作量很大。
所以,我观察,华为先做了这样一件事情:
大模型相关的大概就三四百个接口。
这也是一个不小的工作量。
先将大模型相关的框架接口对齐。
想全面对齐,就这个框架接口的数量级,
若不是体量大的公司,大举挥师,
很难拿下这样工程量的山头。
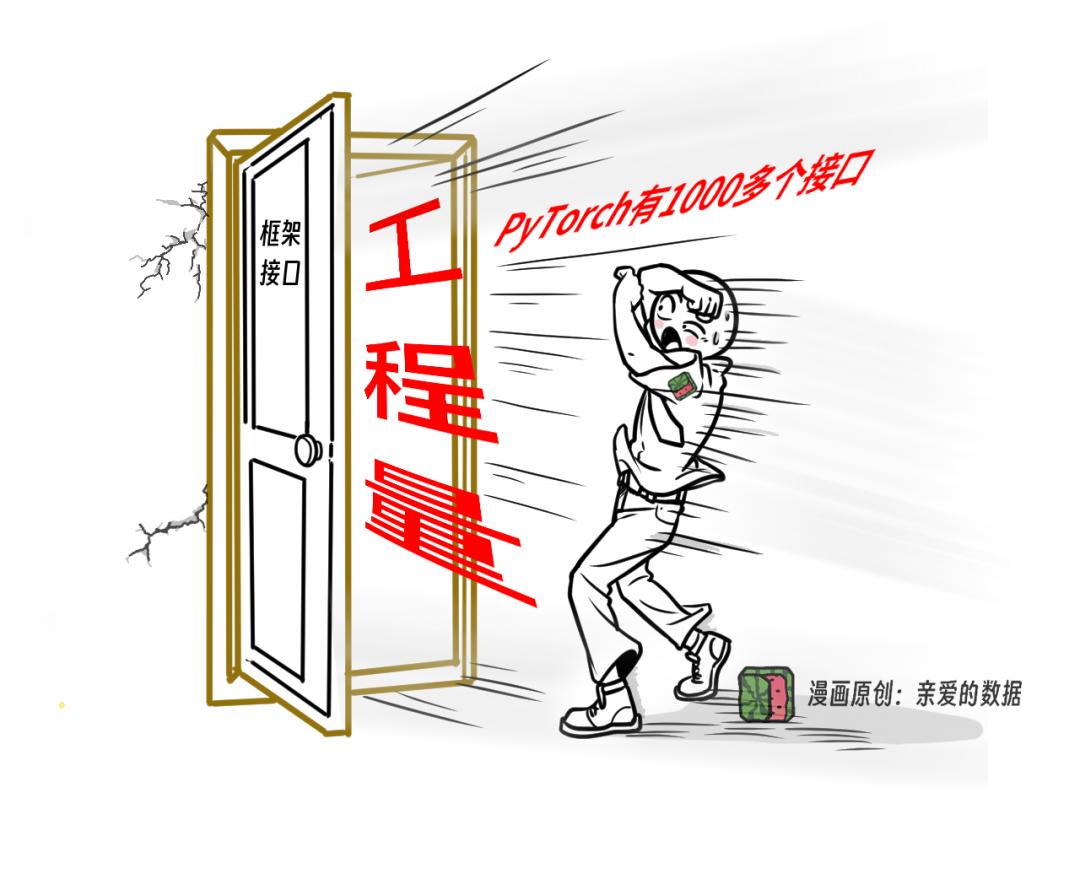
另外,在大模型时代,
这些“流水线”已经复杂得很不像话了:
比如,大模型训练需要把任务,
分布到几十上百块GPU上,
每块GPU干啥,框架接口得安排得明明白白。
没有这些优化,硬件就像一群分工混乱的工人,
干活慢,还乱用资源。
再比如,
框架接口如果调用得不好,
性能立马掉一截。
不仅是个接口,
而是通过这些接口将硬件性能最大化释放。
写到这,大家也明白了。
有些技术追赶,
需要用大批量的、高质量的工程追赶。
没有那么多弯道给你超车,
他们建设得早,路是他们的,车也是他们的。
建我们的道,
造我们的车。
超车需要的是长期耐心和投入。
框架接口的战场打的是什么?
要我看,谁敢小瞧框架接口?
它打的是基本面。

06
静态图与动态图
说框架,绕不过接口,
更绕不过静态图和动态图。
这里一直存在不少历史遗留问题,
而且是个话题终结者。
一般都不愿意看这么细,这么深,
其实里面大有洞天。
这就像你是一个电影导演:
动态图是边拍,边调剧本。
静态图是先定稿剧本,再去成片。
为什么说做框架难?
从表面上看,只需要告诉框架“我想训练啥模型”,
它就会帮你自动(把代码、数据、硬件资源组织好),让模型跑出结果,而不用操心底层的数学运算和硬件适配。
这种“自动化”的背后,
绕不开静态图和动态图。
但从更高的产业视角来看,它们不仅是技术选择,
PyTorch的江山就是靠动态图打下来,
门槛低,好用。
不是非得六边形战士才能用。

动态图,好比,做题,做一步,
翻看一次答案,
错了就是随时改,
越做越有信心。
或者另一种方式是,
一道题算了三天三夜,才能对答案,改错题。
后者更适合学霸。
这种玩法,
游戏难度太大,玩家就少了。
于是,谁静态图起家,
谁就吃了生态上的大亏。
很难讲谁吃的亏更大。
因为谷歌JAX和昇思MindSpore在这件事情上,
它俩想法又一样。
(此处又不礼貌地笑了)
它们都是在执行的时候尽量变成静态图去执行。
静态图主打“规划好一切才准许行动”。
因为框架不仅要理解用户的代码,
还要判断如何用最优的方式在硬件上执行。
而且静态图是自动并行的基础,
自动并行是大模型对框架的核心需求之一。

再细看MindSpore,
到昇腾AI处理器第二代,
全面支持动态图的时候,相当于有个负担。
也就是说,昇思MindSpore针对昇腾第二代AI处理器去做设计的时候,
对静态图投入了大量精力。
动态图虽然有,性能不太好,别人也不会用。
谈易用性,是在性能还能用的情况下,
并不是在性能不能用的情况下奢谈易用性。
也就是说,现在会继续发展原先静态图的优势,而短板也要补。
不过,一切都需要时间。
聊到这里,理解MindSpore在忙啥了吧?
也理解PyTorch在忙啥了吧?
再总结一下,PyTorch忙活两件事,
第一要事,拼命搞它的静态图。

07
谁在掏空PyTorch?
接上文,PyTorch还忙着搞另一件事,
拼命想把并行库移到“框架里”。
猛一看,什么叫做“框架里”?
说来话长。
作为AI框架的“一哥”,
在设计初期,并没有直接支持并行计算的能力。
为什么?
因为早期没必要,现在很有必要。
早期还没大模型呢,
软件这件事就是,你不解决,有的是人帮你解决。
没有原生并行能力的PyTorch,
吸引到Megatron前来。
这个有靠山的兄弟来了,看似局面稳了。
也就是说,当你需要让模型跑在多张GPU上并行训练时,PyTorch本身是帮不上太多忙的——这个活儿,靠的是像Megatron这样的“专业外包选手”。
Megatron是什么?
是英伟达开发的一个库,用于搞定大模型的并行计算。也可以叫它第三方库。
当你要训练大家伙(Transformer)的时候,
Megatron会帮你把模型的参数,
数据和计算任务切分到不同的GPU上,
同时保证结果一致。
不过该来的总该要来,
谁是底层,谁就容易无感。
底层软件的宿命,就是被用得天经地义,却无人留意。除非上面一层,仍然是自己人。
常言道,我和你一条船,不代表我和你一条心。
Megatron是英伟达的。
假如,我是说假如,Megatron这种并行库,
连MindSpore都能对接了,
假如人家MindSpore还做得好,
那么MindSpore+Megatron行不行?
因为开发者只感受Megatron,底下用啥框架都可以。
终于,PyTorch意识到了,
战略要地,怎么能留给别人插旗?
Megatron看似驻扎在PyTorch的地盘上,
但归根结底,它还是英伟达的“亲兵”。
别看现在在开源生态里打得风生水起,
关键时刻,这兵马终究要听号令回归主阵营。
说白了,Megatron扎根在PyTorch,
平时帮着干活,一旦局势有变,
还是要为自家阵地开路。

于是,PyTorch拼命补课,
把并行能力“嵌入”到框架里,成为原生功能。
这样,不需要外接Megatron这样的库,
开发者也能直接用PyTorch写出支持多GPU并行的大模型。
为什么并行能力对PyTorch很重要?
对谁都很重要,这是时代的要求,
世人皆知,模型太大,
但是模型大不是结果,而是需求的特点。
另一个变量,无声登场,
而这个变量,才是真正的大杀器。
假如大模型的结构在逐渐固定,“逐渐”二字重读,
打破“逐渐”则需要创新力。
若模型结构趋于不变,
开发者不再需要频繁改动底层框架逻辑,
而是更多关注性能优化和并行计算。

这点对“AI芯片影响更大”,
但因为框架和芯片的“垂直整合”是另一层面的分析,
此处按下不表。
如果PyTorch的并行能力总是靠Megatron,
那么开发者的关注点会转移到Megatron上。
久而久之,PyTorch的存在感会被削弱。
乍一看,AI框架的江湖,
PyTorch似乎已是“一代霸主”,
仿佛尘埃落定。
但事实远非如此。
欲戴王冠,必承其重,
暗潮涌动,未必稳固。
你再看JAX框架,
技术路线是并行和编译这些能力都放在框架本层里,且是静态图加自动并行。
巧了,谷歌JAX的思路又跟昇思MindSpore一样。

刚才说了,PyTorch框架当下最重要的工作,
其一,做静态图(编译),
由此可见,其二是把并行做回框架本层来。
诚如所见,
PyTorch新版本特性集中反映在两个聚焦点上。
08
开发者随
上层“迁移”
细想想,HuggingFace的崛起,
代表了AI开发从“框架中心”向“模型中心”迁移。
要我说,这种变化间接“架空”了PyTorch在开发者中的直接影响力。
HuggingFace的核心价值,
是把复杂的AI模型封装成易用的工具库和API,
开发者无需深入底层,
只需调用HuggingFace模型接口,就能干活。
PyTorch虽然强大,
但直接在上面开发颇有门槛,
不是说上手就会。
当HuggingFace的模型库和工具,
成为开发者的入口,
PyTorch则沦为底层执行引擎,
成了看不见的“发动机”,
HuggingFace成了摸得到的“驾驶舱”。
这意味着,PyTorch将生态主导权部分让出。
说实话,我怎么就感觉PyTorch越来越“薄”了呢?
你们说呢?

06
其他没机会了?
都说千秋霸业,
霸业再盛,若不随势而动,
也难保江湖恒久敬畏。
生态位的竞争变了,
开发者的关注点就转移了。
PyTorch确实不绑定特定硬件,
但是,AI框架跟硬件强相关。
但芯片厂商为了吸引开发者,开发了特定的异构计算架构。比如,英伟达的CUDA,AMD的ROCm,甚至华为的CANN。
而且,事物有两面性。
如果框架缺乏硬件支持,
其使用体验和性能都会受到影响。
框架的广泛应用离不开对不同硬件的适配,
而适配程度直接影响框架的竞争力。
PyTorch没有硬件,而硬件架构演进很快,
比如,超节点,
UMA(统一内存架构),
Dataflow(美国AI芯片公司Sambanova架构)等等,框架如何快速适配?
多说一句,尤其在中国,
有很多国产芯片,正在备尝艰苦。
假如模型结构固定的话,
玩几个“经典款”就够了。
Llama或千问很有潜力。
我目之所及,无论中国的,还是美国的,
很多大甲方的基础模型就选这两个。
只要你能给出最优解,我就选你。
只要AI框架自带一个优秀的Llama组件,
只要这个标准组件的性能比PyTorch原生的Llama提升15%。大家都很“现实”,当“标准模型”成熟,开发者根本不关心它是用什么框架写的。他们只想知道:哪种框架能让我用的模型跑得更快?

若模型结构固定,
这个AI框架(软件)和AI芯片(硬件)做垂直整合,就有机会做出新优势。
因为硬件厂商了解自家芯片的每一个细节,
框架可以针对芯片特性做极致优化。
而PyTorch这种中立框架需要支持各种硬件,
优化时得考虑兼容性。
它也不可能为某一个硬件优化。
而JAX背后有谷歌TPU芯片,
MindSpore背后有昇腾AI处理器。
AI框架的未来,并不是单纯拼生态广度。
是谁能在“模型固定后”的赛道上,
跑得更快、更远、更稳。
当下,模型是处于收敛和不收敛的中间状态,
不是说模型结构不变,而是它还在演进,
中间状态,多方战况焦灼。
不得不说,苹果的AI框架MLX,
Github上看,热度涨得很快,不要小瞧。
苹果MLX框架可面向个人开发者,或是小企业,
群体很大,抓住了,又有苹果的硬件和全系统的支持,相对小(1TB)的模型就可在上面训练,做微调。苹果这个例子说明了什么呢?
“垂直整合”。
()
不过,苹果MLX框架+服务器芯片,
才开始搞,还要再观察,而且,苹果在端上的优势,是另一个故事了《AI推理篇》。将苹果的MLX框架集成于M系列芯片中,猛搞终端推理优化。
这种策略虽然不抢占大模型训练市场,但在iPhone、iPad上构筑强大封闭生态。放眼望去,这条路也能走出大生态。
同理也适用于谷歌JAX和昇思MindSpore。
至于PyTorch,最近有点烦。
(完)
One More Thing
2024年2月,我已有一个以PyTorch被“掏空”为选题的写作计划。
不过,因为写作难度大,访谈难度高,久未成稿。
“新闻不是一天发生”,没想到仅过一年,
局面基本可以确定如此,喟然一叹,
这又是一个量变引起质变的故事,
世间万事,莫过如此。






